Deep Dive into Large Language Model Architecture: Unveiling the Secrets of LLMs
A detailed exploration of the architecture of Large Language Models (LLMs), breaking down the key components, mechanisms, and training processes that power these powerful AI systems.
Unpacking the Black Box: A Deep Dive into Large Language Model Architecture
Introduction
Large Language Models (LLMs) have taken the world by storm, demonstrating remarkable capabilities in natural language understanding and generation. From writing compelling text and translating languages to answering complex questions and generating code, LLMs are rapidly changing how we interact with technology. But behind their impressive performance lies a complex and fascinating architecture.
Understanding the architecture of LLMs is crucial for anyone working with or interested in the field of Artificial Intelligence. It allows us to appreciate their strengths and limitations, fine-tune them effectively, and even contribute to their future development.
This post aims to demystify the inner workings of LLMs, providing a detailed and extended exploration of their architecture, key components, and the training processes that bring them to life.
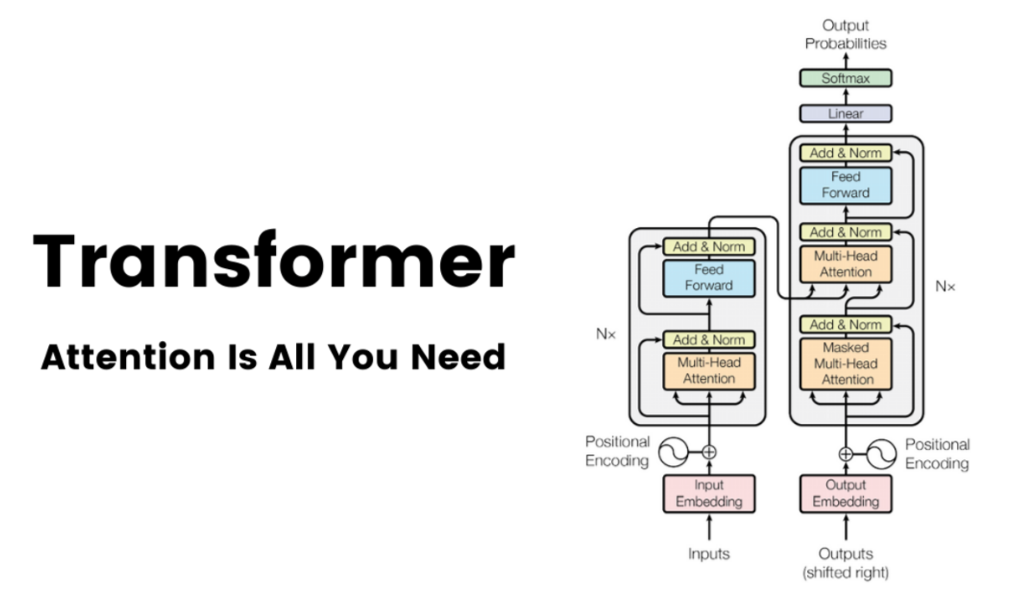
The Transformer: The Cornerstone of Modern LLMs
At the heart of almost every modern LLM lies the Transformer architecture. Introduced in the groundbreaking paper "Attention is All You Need" in 2017, the Transformer revolutionized natural language processing by moving away from recurrent neural networks (RNNs) and embracing attention mechanisms.
Attention Mechanism: Focusing on What Matters
The core innovation of the Transformer is the attention mechanism, particularly self-attention. Imagine you are reading the sentence: "The cat sat on the mat because it was comfortable." To understand "it", you need to refer back to "mat". Attention mechanisms allow the model to do something similar – to weigh the importance of different words in the input sequence when processing each word.
Self-Attention in Detail:
-
Input Embeddings: The input sentence is first converted into numerical representations called word embeddings. Each word is mapped to a vector in a high-dimensional space, capturing its semantic meaning. We'll discuss embeddings in more detail later.
-
Key, Query, and Value Vectors: For each input word embedding, three vectors are created: Query (Q), Key (K), and Value (V). These are linear transformations of the input embedding, learned during training. Think of them as different perspectives of the word's representation.
-
Calculating Attention Weights: For each word (query), we calculate its compatibility score with every other word (keys) in the input sequence. This is typically done by taking the dot product of the Query vector of the current word with the Key vectors of all other words. These scores are then scaled down (often by the square root of the dimension of the key vectors) to stabilize training and passed through a softmax function. The softmax function converts these scores into probabilities, representing the attention weights. These weights signify how much each word should "attend" to every other word when processing.
-
Weighted Sum of Value Vectors: Finally, for each word, we compute a weighted sum of the Value vectors of all words in the input sequence. The weights used in this sum are the attention weights calculated in the previous step. This weighted sum becomes the output of the self-attention mechanism for that word. It's a context-aware representation of the word, influenced by its relationships with other words in the sentence.
Multi-Head Attention:
To capture more complex relationships and patterns in the data, Transformers employ multi-head attention. Instead of having just one set of Query, Key, and Value transformations, there are multiple sets – "heads." Each head performs self-attention independently, learning different aspects of word relationships. The outputs of all heads are then concatenated and linearly transformed to produce the final output of the multi-head attention layer. This allows the model to attend to different parts of the input sequence in parallel, enriching the representation.
Transformer Block: The Building Block
LLMs are built by stacking multiple Transformer blocks on top of each other. A typical Transformer block, especially in decoder-only architectures (like GPT models), consists of the following layers:
-
Multi-Head Attention Layer: As explained above, this layer computes the context-aware representations of the input sequence using multi-head self-attention.
-
Add & Norm (Add and Layer Normalization): The output of the multi-head attention layer is added to the original input of this sub-layer (residual connection). This helps with gradient flow during training and allows the model to learn identity mappings. The result is then passed through a Layer Normalization layer. Layer normalization stabilizes training by normalizing the activations within each layer.
-
Feed-Forward Network (FFN): This is a simple, position-wise feed-forward network. "Position-wise" means that the same FFN is applied to each position in the sequence independently. It typically consists of two linear transformations with a non-linear activation function (like ReLU or GeLU) in between. The FFN helps to further process the context-aware representations and introduce non-linearity.
-
Add & Norm (Add and Layer Normalization): Similar to the attention sub-layer, the output of the FFN is added to the input of the FFN (another residual connection) and then passed through a Layer Normalization layer.
These Transformer blocks are stacked repeatedly (e.g., 12, 24, 48, or even more layers in very large models) to create deep networks capable of capturing intricate patterns in language.
Decoder-Only Architecture: The Dominant Design for LLMs
Most powerful LLMs today, like the GPT family and Llama models, utilize a decoder-only Transformer architecture. This architecture is primarily designed for autoregressive language modeling. Autoregressive means the model predicts the next word in a sequence based on the words that have come before it.
Decoder-Only Structure:
- Stacked Decoder Blocks: The decoder-only architecture essentially consists of a stack of Transformer decoder blocks.
- Masked Self-Attention: A crucial modification in the decoder block for autoregressive modeling is masked self-attention. In standard self-attention, each word can attend to all other words in the input sequence. However, for autoregressive generation, when predicting the next word, the model should only have access to the words that precede it, not the words that come after. Masked self-attention achieves this by masking out (preventing attention to) future words in the sequence during the attention calculation. This ensures that the model learns to predict the next word based only on the past context.
- No Encoder: Unlike the original Transformer, decoder-only architectures do not have a separate encoder component. They process the input sequence directly through the stacked decoder blocks.
How Decoder-Only LLMs Generate Text:
- Input Prompt: The process starts with an input prompt – the initial text provided to the model.
- Encoding and Processing: The prompt is tokenized (split into words or sub-word units), converted into embeddings, and passed through the stack of decoder blocks.
- Next Word Prediction: The final decoder block produces probabilities for each word in the vocabulary being the next word in the sequence.
- Sampling: A sampling strategy (e.g., greedy sampling, top-k sampling, nucleus sampling) is used to select the next word from the probability distribution.
- Iterative Generation: The selected word is appended to the input sequence, and the process is repeated. The model now takes the extended sequence as input and predicts the next word again. This iterative process continues until the model generates an end-of-sequence token or reaches a predefined length limit.
Beyond Transformers: Essential Components
While the Transformer architecture is the core, several other components are crucial for the functioning of LLMs:
1. Embedding Layer: Representing Words Numerically
The embedding layer is the first layer of the LLM. It's responsible for converting discrete input tokens (words or sub-word units) into continuous vector representations – word embeddings.
- Learned Embeddings: In modern LLMs, embeddings are typically learned during the pre-training process. The embedding layer is essentially a lookup table where each token in the vocabulary is associated with a learned vector.
- Semantic Meaning: These learned embeddings are designed to capture semantic relationships between words. Words with similar meanings are placed closer to each other in the embedding space.
- Dimensionality: Embedding vectors are typically high-dimensional (e.g., hundreds or thousands of dimensions) to capture rich semantic information.
2. Positional Encoding: Injecting Sequence Order
Transformers, unlike RNNs, do not inherently process sequential information in order. The attention mechanism operates on all input tokens simultaneously. Therefore, to inform the model about the position of words in the sequence, positional encodings are added to the input embeddings.
- Mathematical Functions: Positional encodings are typically generated using mathematical functions like sine and cosine waves of different frequencies. These functions produce unique patterns for each position in the sequence.
- Adding to Embeddings: These positional encoding vectors are added element-wise to the word embeddings before they are fed into the Transformer blocks. This injects positional information into the representation, allowing the model to differentiate between words based on their order in the sentence.
3. Output Layer: Predicting Probabilities
The final layer of an LLM is the output layer. Its role is to convert the final representations from the Transformer blocks into probabilities over the vocabulary.
- Linear Layer: Typically, a linear layer is applied to the output of the last Transformer block. This linear layer projects the high-dimensional representations back to the vocabulary size.
- Softmax Function: The output of the linear layer is then passed through a softmax function. The softmax function converts the raw scores into probabilities. Each probability in the output vector represents the model's confidence that the corresponding word in the vocabulary is the next word in the sequence.
Training LLMs: Pre-training and Fine-tuning
Training LLMs is a computationally intensive process that typically involves two main stages: pre-training and fine-tuning.
1. Pre-training: Learning General Language Representations
-
Unsupervised Learning: Pre-training is typically done in an unsupervised manner on massive amounts of text data from the internet (e.g., books, articles, websites, code). The model learns general patterns and structures of language from this vast dataset without explicit human labels.
-
Pre-training Tasks: Common pre-training tasks for decoder-only LLMs include:
- Causal Language Modeling (CLM): The model is trained to predict the next word in a sequence given the preceding words. This is essentially the autoregressive language modeling task we discussed earlier. The model learns to capture dependencies and relationships between words in a sequential context.
- (Historically) Masked Language Modeling (MLM): While less common for decoder-only architectures, some LLMs (like BERT, which is encoder-only) use MLM. In MLM, a certain percentage of words in the input sequence are randomly masked out, and the model is trained to predict the masked words based on the surrounding context.
-
Massive Datasets and Computation: Pre-training requires enormous datasets and significant computational resources (powerful GPUs or TPUs) and can take weeks or months to complete.
2. Fine-tuning: Adapting to Specific Tasks
- Supervised Learning: After pre-training, the LLM has learned general language representations. To make it perform well on specific downstream tasks (e.g., text classification, question answering, text summarization, translation), it needs to be fine-tuned. Fine-tuning is a supervised learning process.
- Task-Specific Datasets: Fine-tuning is performed on smaller, task-specific datasets with labeled examples. For example, for sentiment analysis, the fine-tuning dataset would consist of text examples labeled with their sentiment (positive, negative, neutral).
- Adjusting Pre-trained Weights: During fine-tuning, the pre-trained weights of the LLM are adjusted to optimize its performance on the specific task. Typically, a smaller learning rate is used during fine-tuning compared to pre-training to avoid drastically changing the learned representations.
Scaling Laws and Model Size
A significant factor in the performance of LLMs is their size, often measured by the number of parameters. Scaling laws have been observed in LLMs, indicating that performance generally improves as model size, dataset size, and training compute increase.
- More Parameters, More Capacity: Larger models with more parameters have a greater capacity to memorize information and learn complex patterns in the data.
- Emergent Abilities: Larger LLMs have shown "emergent abilities" – capabilities that are not apparent in smaller models but emerge as the model size increases. These abilities can include more sophisticated reasoning, few-shot learning, and improved generalization.
- Computational Cost: However, larger models also require significantly more computational resources for training and inference, leading to higher costs and longer processing times.
Challenges and Future Directions
Despite their impressive capabilities, LLMs still face challenges:
- Bias and Fairness: LLMs can inherit biases from their training data, leading to unfair or discriminatory outputs.
- Hallucinations: LLMs can sometimes generate factually incorrect or nonsensical text (hallucinations).
- Computational Cost and Efficiency: Training and deploying very large LLMs are computationally expensive and energy-intensive.
- Interpretability and Explainability: Understanding why LLMs make certain predictions is still a challenge.
Future research directions in LLM architecture include:
- Improving Efficiency: Developing more efficient architectures and training techniques to reduce computational costs.
- Enhancing Reasoning and Factuality: Improving the reasoning abilities and reducing hallucinations in LLMs.
- Addressing Bias and Fairness: Developing methods to mitigate bias and ensure fairness in LLMs.
- Improving Interpretability: Making LLMs more interpretable and explainable.
- Exploring Novel Architectures: Investigating new architectural innovations beyond the Transformer.
Conclusion
Large Language Models are complex and powerful AI systems built upon the foundation of the Transformer architecture. Understanding their inner workings, from attention mechanisms and Transformer blocks to pre-training and fine-tuning, is essential for navigating the rapidly evolving landscape of AI. As research continues to advance, we can expect further innovations in LLM architecture, leading to even more capable and beneficial AI systems in the future.
If you are fascinated by the intricacies of AI, deep learning architectures, and the power of language models, let's connect! ( ^-^)**(^0^ )
Thank you for reading this deep dive into LLM architecture! Your questions and insights are always welcome. ╰(°▽°)╯